MGiaD: Multigrid in all dimensions - Efficiency and robustness by weight sharing and coarsening in resolution and channel dimensions
Antonia van Betteray2 • Matthias Rottmann2 • Karsten Kahl1
1 Applied Computer Science Group, University of Wuppertal, Wuppertal, Germany
2 Computer Vision and Robust AI Lab Osnabrueck University - Institute of Computer Science
Workshop on Resource Efficient Deep Learning for Computer Vision, ICCV Workshop, 2023

Abstract
Deep convolutional neural networks (CNNs) for image classification are made up of 10–100 million learnable parameters, i.e. weights. Despite their high classification accuracy these networks are heavily overparameterized. Thus, a reduction in weight count is desirable, however it may induce an undesirable bias. This trade-off is referred to as “bias-complexity trade-off”, which constitutes a fundamental problem of machine $\text{learning}^2$. We address this problem by introducing a CNN architecture that achieves a more favorable bias-complexity trade-off, in terms of an accuracy-weight trade-off, by exploiting $\text{multigrid}^3$ inspired ideas. Similar to state-of-the-art architectures, its weight count scales linear in the resolution dimensions and substantial reductions are achieved by appropriate weight sharing. A hierarchical structure w.r.t.the channel dimensions facilitates linear scaling of the weight count. In combination, we obtain an architecture whose number of weights scales only linearly in all relevant dimensions, i.e., the input resolution and number of available channels. We introduce an architecture that establishes multigrid structures in all relevant dimensions, contributing a drastically improved accuracy-parameter trade-off. Our experiments show that this structured reduction in weight count reduces overparameterization and additionally improves performance over state-of-the-art ResNet architectures on typical image classification benchmarks.
Method Overview
The solution $u$ of large system of (non)-linear equations $Au=f$, with $A$ the system matrix and $f$ the right-hand side, is approximated iteratively via stationary iterative schemes $$ u^{(i+1)} = u^{(i)} + B(f- Au^{(i)}), \;\;\; i = 0,1, ...,$$ where $f - Au^{(i)}$ is called the residual.
Typically $B \approx A^{-1}$ and the (unknown) error is propagated in each iteration as $$ e^{(i)} = (I - BA) e^{(i)}.$$ The system matrix $A$ does not change with the iteration, the operator $B$ can be changed with the iteration.
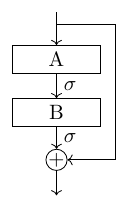
The factor $(I-BA)$ structurally resembles a ResNet-block, where $A$ and $B$ are learnable convolutions. Nevertheless, the structural similar yields motivation for reusing the operators $A$ and $B$ ins ResNet-blocks. Though iterative methods are characterized by a fast decay of the error in the first iterations (smoothing), they suffer from a drastic decrease of the convergence rate. To speed up convergence, solutions from coarser resolutions are used to approximate the true solution. To that end the residual is restricted to the next coarser resolution level $\ell + 1$ as $r_{\ell + 1} = R_\ell^{\ell +1}e_{\ell}$, where the restriction operator $R_\ell^{\ell +1}$ is a pooling operation. The residual problem on the coarse grid is solved directly and with the coarse-grid solution the approximated solution on the fine grid is corrected accordingly. Recursively repeating this scheme yields a multi-grid structure.
Since we deal with non-linear problems in deep learning, an initial guess for the solution on the coarser resolution is required, given by $u^{\ell +1} = \Pi_\ell^{\ell +1}$.
Multigrid in CNNs
In deep learning we assume that data $f$ and features $u$ are related by (convolutional) mappings $A$ and $B$, which can be chosen as $$A: \mathbb{R}^{m \times n \times c} \rightarrow \mathbb{R}^{m \times n \times h}, \text{s.t. } \; A(u) =f$$ $$B: \mathbb{R}^{m \times n \times h} \rightarrow \mathbb{R}^{m \times n \times c}, \text{s.t. } \; u \approx B(f) \;$$
Where $m$ and $n$ are the input/output feature map dimensions and $c$ and $h$ the number of in- and output channels respectively.
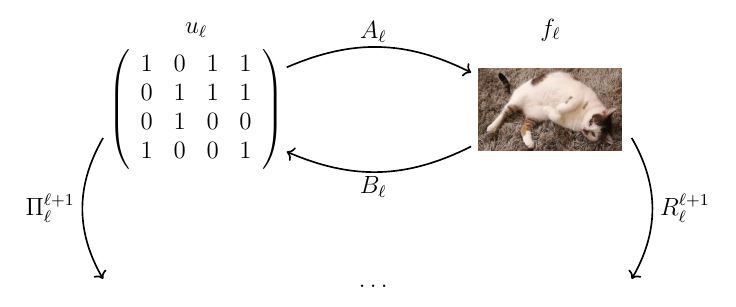
Besides the structural analogy in MG the operations $A,B$ and $f$ are given and the solution $u$ is sought. On the other hand in deep learning $f$ and $u$ are given, and we want to learn $A$ and $B$. The transfer operators are pooling operators, where the $R_{\ell}^{\ell +1}$ operates on the data domain and $\Pi_{\ell}^{\ell+1}$ operators on the feature domain.
These mappings can be used to construct iterative schemes, i.e., residual blocks.
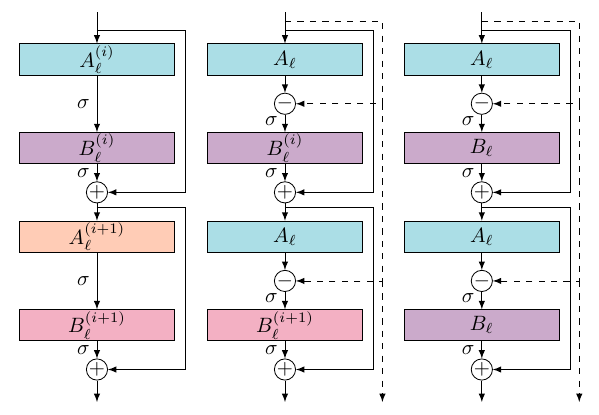
By reusing the operators $A$ and or $A$ and $B$ a significant reduction of weights with marginal loss in accuracy can be achieved, However the weight count scales quadratically with respect to the number of channels as $A$ and $B$ are convolutions with a $k^2$ of size $c \times h \times k^2$. Due to their local action, convolutions are sparse in the resolution dimension and dense in the channel dimension as each input channel couples with each output channel.
| Dataset | Model | No. of weights | Acc. (%) |
|---|---|---|---|
| CIFAR10 | ResNet18 | \(11{,}175k\) | \(\mathbf{96.26}\) |
| \(\text{MgNet}^{A}\) | \(4{,}115k\) | \(96.02\) | |
| \(\text{MgNet}^{AB}\) | \(2{,}751k\) | \(96.00\) |
Smoothing in Channels ($\mathtt{Sic}$)
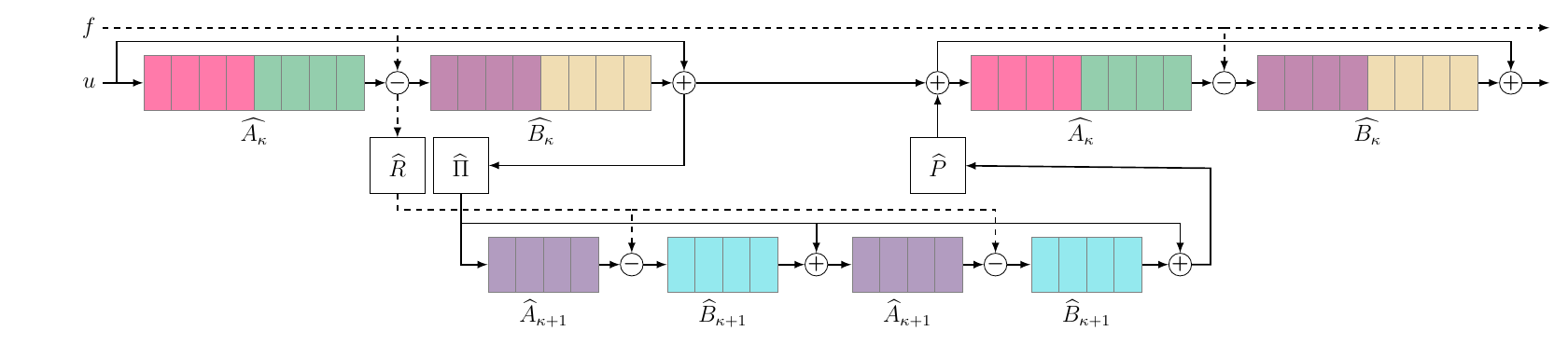
To achieve sparsity in the channel dimension we construct a hierarchical MG structure build from grouped convolutions. The number of channels is successively reduced until fully coupled convolutions are reasonable, which restore channel interaction and ensuring information exchange. On each in channel level: smoothing with shared weights ($\mathtt{Sic}$). Fully coupled convolutions on the coarsest in channel levels correspond to direct solving in MG. One smoothing in channel hierarchy replaces one MgNet-block.
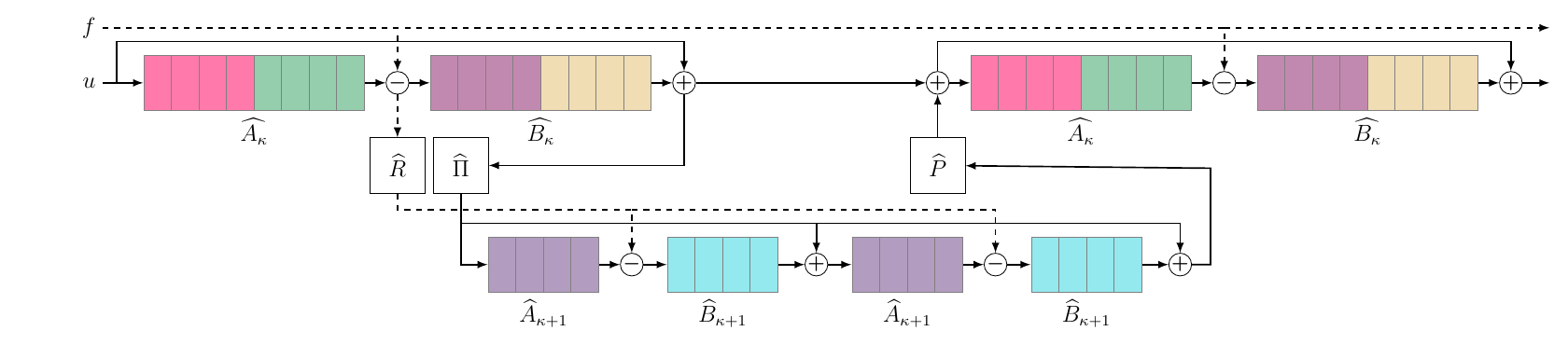
\(\mathtt{SIC}\)-block on one resolution level with \(\kappa = 2\) channel levels. The convolutions \(\widehat{A}\) and \(\widehat{B}\) are in groups of size \(4\), indicated by different colors. On each level, \(\widehat{A}\) and \(\widehat{B}\) are shared between pre-smoothing (left leg) and post-smoothing (right leg), respectively. Operators on the second, coarser level are different from the first level, but also shared. The transfer operators \(\widehat{\Pi}\) and \(\widehat{R}\) halve the number of channels, and the prolongation mapping \(\widehat{P}\) doubles the number of channels.
Qualitative Results
In order to improve the accuracy-weight trade-off we perform a hyperparameter studies regarding the group size ($g_s$) in grouped convolutions as well as the number of fully coupled channels ($c_K$) on the coarsest in channel level. In order to utilize the freed-up weight capacity induced by grouped convolutions we use a channel scaling parameter $\lambda$ to multiplicatively adapt the number of channels.
For different models trained on CIFAR10 we make the following observations:
- ResNet18 achieves a high classification accuracy, but requires a lot of weights. A reduction in weight count yields in a reduction in accuracy.
- $\text{MgNet}^{AB}$ achieves similar accuracy as ResNet18 but with way less weights.
- MgNet with a reduced weight count induced by grouped convolutions suffers from a drastic reduction of accuracy
- MGIC achieves an improved accuracy-weight trade-off compared to MgNet with a hierarchical structure in the channel dimension
- Our MGiAD models achieve comparable accuracy to MgNet and ResNet with a significant reduction in the weight count. They also achieve a higher accuracy compared to MGIC with the same number of weights.
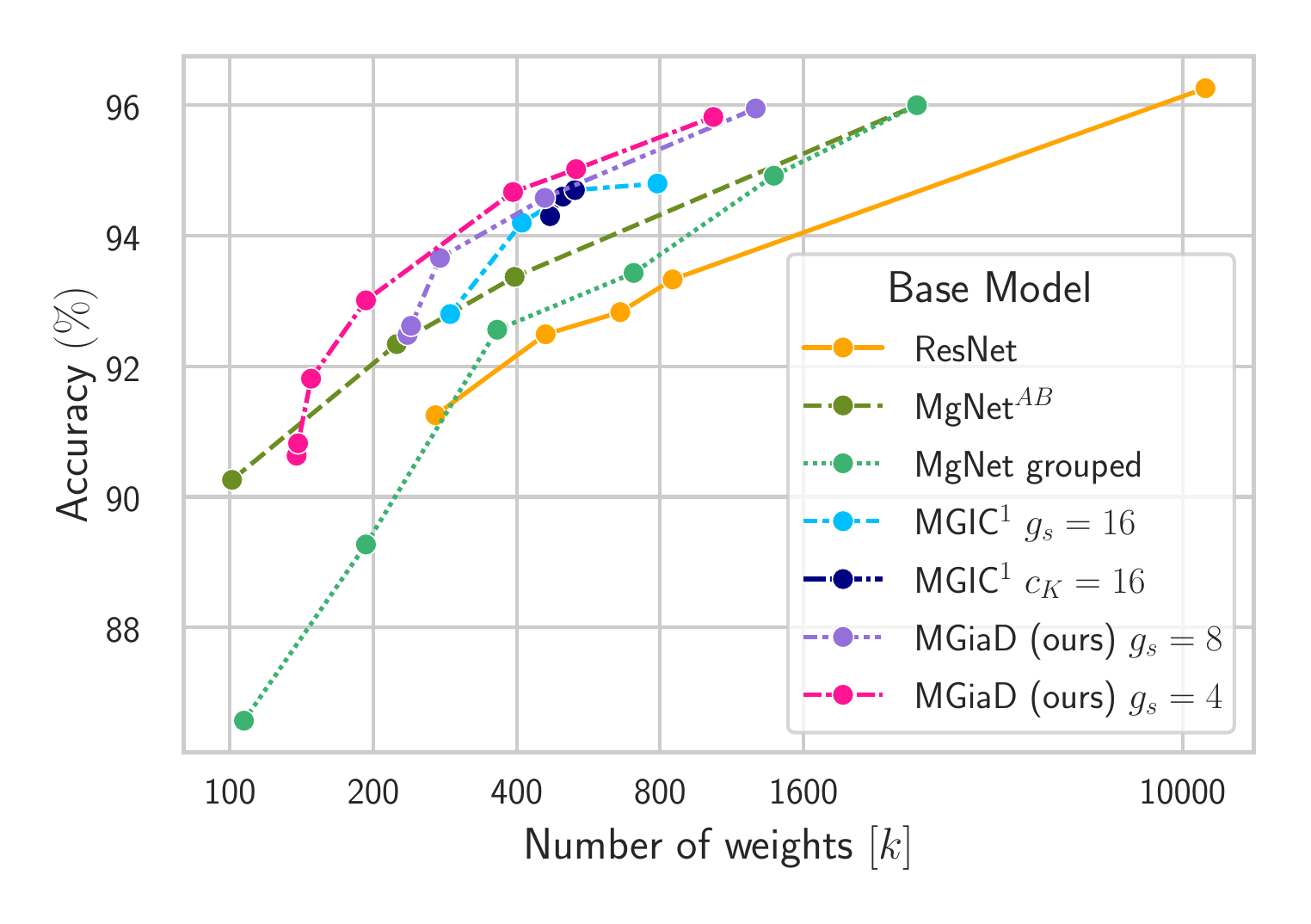 Accuarcy-weight trade-off on CIFAR-10 for different ResNet, MgNet, MGIC and MGiaD models. For MGiaD the group size $g_s \in\{4, 8\}$ is fix and the number of channels $c_K$ varies. An optimal model lies in the upper left corner.
Accuarcy-weight trade-off on CIFAR-10 for different ResNet, MgNet, MGIC and MGiaD models. For MGiaD the group size $g_s \in\{4, 8\}$ is fix and the number of channels $c_K$ varies. An optimal model lies in the upper left corner.
These results generalize to bigger problems. Two key observations we make is that a small group sizes results in a low weight count and that on the other hand a sufficient big $c_K$ is crucial for a high accuracy.
| Dataset | Model | No. of weights | Acc. (%) |
|---|---|---|---|
| CIFAR100 | ResNet18 | \(11,\!220k\) | \(75.42\) |
| \(\text{MgNet}^{AB}\) | \(2,\!774k\) | \(74.42\) | |
| \(\text{MGiaD}_{1,64}\) | \(1,\!384k\) | \(72.53\) | |
| \(\text{MGiaD}_{3,64}\) | \(4,\!822k\) | \(\mathbf{75.85}\) | |
| ImageNet | ResNet18 | \(11,\!690k\) | \(71.80\) |
| \(\text{MgNet}^{AB}\) | \(3,\!013k\) | \(67.38\) | |
| \(\text{MGiaD}_{1,64}\) | \(1,\!625k\) | \(66.38\) | |
| \(\text{MGiaD}_{3,64}\) | \(5,\!544k\) | \(\mathbf{74.39}\) |
References
$^1$ M. Eliasof, J. Ephrath, L. Ruthotto, and E. Treister, “Mgic: Multigrid-in-channels neural network A. architectures,” SIAM J., Sci. Comput., 2023
$^2$ Shai Shalev-Shwartz and Shai Ben-David. Understanding machine learning: from theory to algorithms. Cambridge University Press, 2014
$^3$ U. Trottenberg, C. W. Oosterlee, and A. Schuller, Multigrid. Elsevier, 2000
$^4$ K. He, X. Zhang, S. Ren, and J. Sun. Deep Residual Learning for Image Recognition. IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), 2016
$^5$ J. He and J. Xu, “Mgnet: A unified framework of multigrid and convolutional neural network,” Science china mathematics, 2019
Resources & Links
Acknowledgments

This work is supported by the German Federal Ministry for Economic Affairs and Climate Action, within the project “KI Delta Learning”, grant no. 19A19013Q.
Citation
@InProceedings{van_Betteray_2023_ICCV,
author = {van Betteray, Antonia and Rottmann, Matthias and Kahl, Karsten},
title = {MGiaD: Multigrid in all Dimensions. Efficiency and Robustness by Weight Sharing and Coarsening in Resolution and Channel Dimensions},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
month = {October},
year = {2023},
pages = {1292-1301}
}
Contact
Have questions or want to collaborate? Reach out: