Does Knowledge About Perceptual Uncertainty Help an Agent in Automated Driving?
Natalie Grabowsky1 • Annika Mütze2 • Matthias Rottmann2
1 Technical University of Berlin, Berlin, Germany
2 Osnabrück University, Osnabrück, Germany
Safe Artificial Intelligence for All Domains (SAIAD 2026)

Abstract
Autonomous agents in real-world settings, such as autonomous vehicles, face perceptual uncertainty that impacts decision-making. While reinforcement learning handles uncertainty in principle, it typically lacks explicit information about current perceptual uncertainty. On the other hand, uncertainty estimation for perception itself is typically directly evaluated in the perception domain, e.g., in terms of false positive detection rates. How the knowledge about (perceptual) uncertainty influences goal-oriented actions is still largely unexplored. This paper investigates how uncertain perception affects agent behavior and how knowledge about uncertainty influences decision-making. In a proxy driving task, we perturb observations to simulate perceptual uncertainty and evaluate agent performance with and without explicitly providing uncertainty indication to the agent. Our experiments show that uncertainty in perception leads to defensive driving, while informing the agent about this uncertainty enables faster, risk-aware behavior adapted to the specific situation.
Method Overview
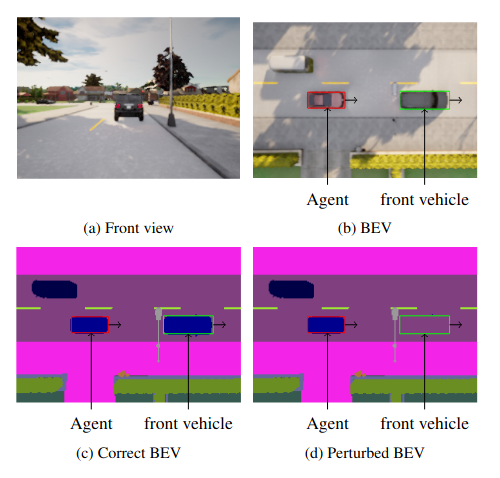
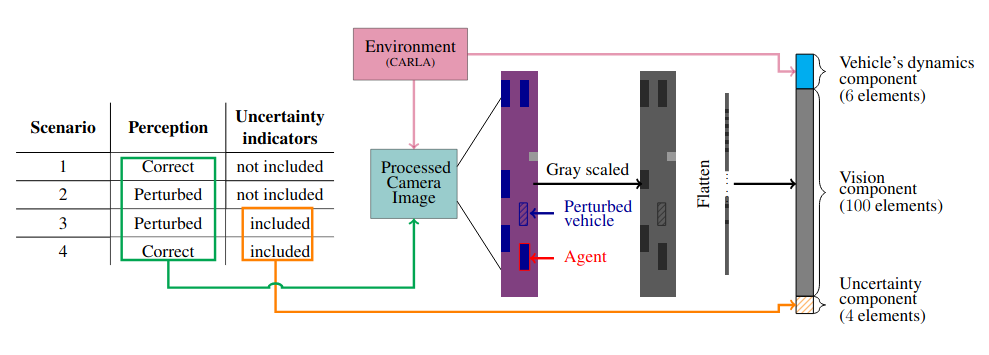
We introduce four different scenarios: 1. The perception of the agent is correct and the uncertainty indicators are not included in the observation space. 2. The perception is perturbed, e.g. vehicles of the agent lane are partially removed, and the uncertainty indicators are not included in the observation space. I.e. the agent is not informed about the case, that its perception is wrong. 3. The agent's perception is perturbed and it is informed about the uncertainty, including uncertainty indicators in the observation space. 4. The agent obtains correct perception while informing it about the uncertainty indicators, i.e. the uncertainty tells the agent, that it is perception is always correct. The 4. case serves as a test case, while the others serve as a train and test case. For learning the policy we use the on-policy PPO algorithm [2]. For each scenario (1-3) we first train the agent for 2 million time steps on its scenario, select the best model based on validation and then test the agent's behavior under different perceptual cases.
Qualitative Results
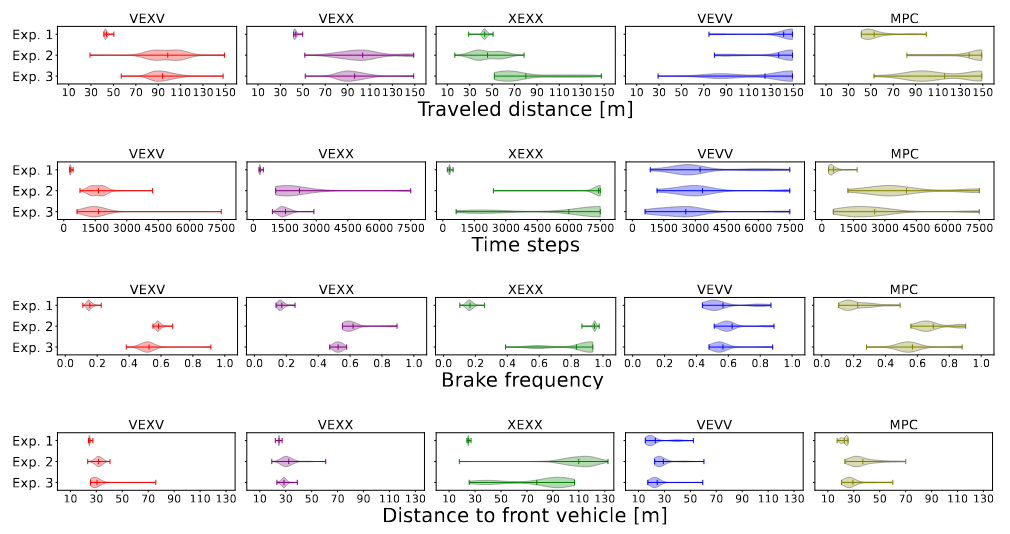
We measure the agent's behavior with four metrics: Traveled distance, time steps, brake frequency and distance to front vehicle.
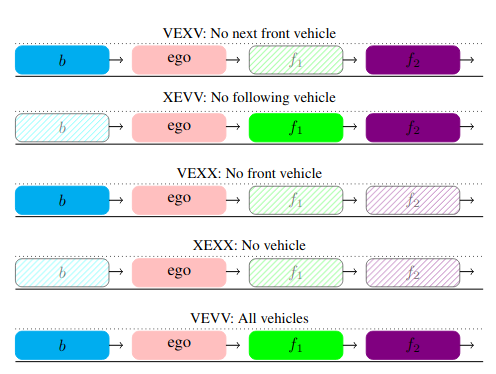
The agent’s behavior in terms of distance traveled, time steps per episode elapsed, frequency of brake action and, the distance to the front vehicle. These are presented for the safety critical cases, the safety case and the MPC case, (indicated in the titles) for experiments 1–3.
Resources & Links
Acknowledgments

All authors gratefully acknowledge the invaluable discussion and support of Joshua Wendland and Nils Jansen from Ruhr University Bochum. Their thoughtful input and rigorous critical review substantially improved the quality of the paper. This work is financially supported by the German Federal Ministry for Research, Technology and Space (BMFTR) within the junior research group project “UnrEAL” (grant no.\ 16IS22069). Additionally, the research leading to these results was partially funded by the German Federal Ministry for Economic Affairs and Energy within the project “NXT GEN AI METHODS – Generative Methoden für Perzeption, Prädiktion und Planung" (grant no.\ 19A23014Q). We thank the human drivers for their reference drives.
Citation
@inproceedings{carla,
title = { {CARLA}: {An} Open Urban Driving Simulator},
author = {Alexey Dosovitskiy and German Ros and Felipe Codevilla and Antonio Lopez and Vladlen Koltun},
booktitle = {Proc. 1st Annu. Conf. Robot Learn.},
pages = {1--16},
year = {2017}
},@article{ppo,
title={Proximal Policy Optimization Algorithms},
author={John Schulman and Filip Wolski and Prafulla Dhariwal and Alec Radford and Oleg Klimov},
year={2017},
journal={arXiv:1707.06347},
eprint={1707.06347},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
Contact
Have questions or want to collaborate? Reach out: